

Chroma + Ollama Local RAG Tutorial
Build your own local RAG system after this tutorial! 🥞

Last week, I wrote a tutorial highlighting that, fundamentally, the "retrieval" aspect of RAG is about fetching data from any system—whether it's an API, SQL database, files, etc.—and then passing that data into the system prompt as context for the user's prompt for an LLM to generate a response.
In this weeks tutorial we are going to expand on this idea and introduce the concept of Vector DBs specifically Chroma and how Chroma can help us store and find the most relevant information to pass to the LLM so it can generate the best response.
Chroma + Ollama RAG Tutorial
Imagine you’ve been tasked with doing a large scale migration for a codebase from JavaScript to TypeScript. Other engineers have been doing this manually by trying to discern the type information themselves. So there is a growing number of TypeScript files with some good type information. This approach is fine, but what if we instead had an LLM convert the files to TypeScript for us. We could probably complete the migration faster. Better yet, what if we could supply the type information we have to the LLM to use as it converts the JavaScript file to TypeScript? Sounds cool.
In this tutorial we are going to simplify everything to convert a single file from JavaScript to TypeScript. But in theory this should scale up to work for the use case we described.
To do this we are going to be utilizing Chroma to help us find source code files that would be useful for the Ollama powered LLM to use when generating a response for converting a file from JavaScript to TypeScript.
📝 Note - All of these technologies are free to use and more secure than using OpenAI or others for these types of conversions.
Here is what the result of the tutorial will look like.

This tutorial is going to use the following technologies. I’ll help you set them up!
Ollama - Easiest way I know of to run LLMs locally on your machine
Chroma - Simple and powerful VectorDB
Node.js - My JS runtime of choice
That’s it! Let’s get started.
Install deps
There are a few dependencies we will need. In your project directory install the following.
pnpm add tsx ai ollama-ai-provider cli-highlight chromadb chromadb-default-embedSince we are using TypeScript to write this we also need the Node.js types.
pnpm add -D @types/nodeExample code
Below is the example JavaScript code we want to convert to TypeScript. This is some simple example code that it is fetching data from an endpoint containing an array of posts.

This example code will be converted to TypeScript using Ollama.
Ollama setup
Go to ollama.com/download to download Ollama for your OS then run the installer.
Once Ollama is installed you need to pull the model we are using in this tutorial. In this case its the qwen2.5-coder:0.5b.
ollama pull qwen2.5-coder:0.5bIt will start downloading. Once successful you can verify its there by listing your models.
ollama listChroma setup
Assuming you have Docker setup locally you can run the commands below. First to download the Chroma image then to run it.
docker pull chromadb/chromadocker run -p 8000:8000 chromadb/chromaScript for conversion from JavaScript to TypeScript
This is the main script that is responsible for converting the JavaScript file to TypeScript using Ollama and Chroma.
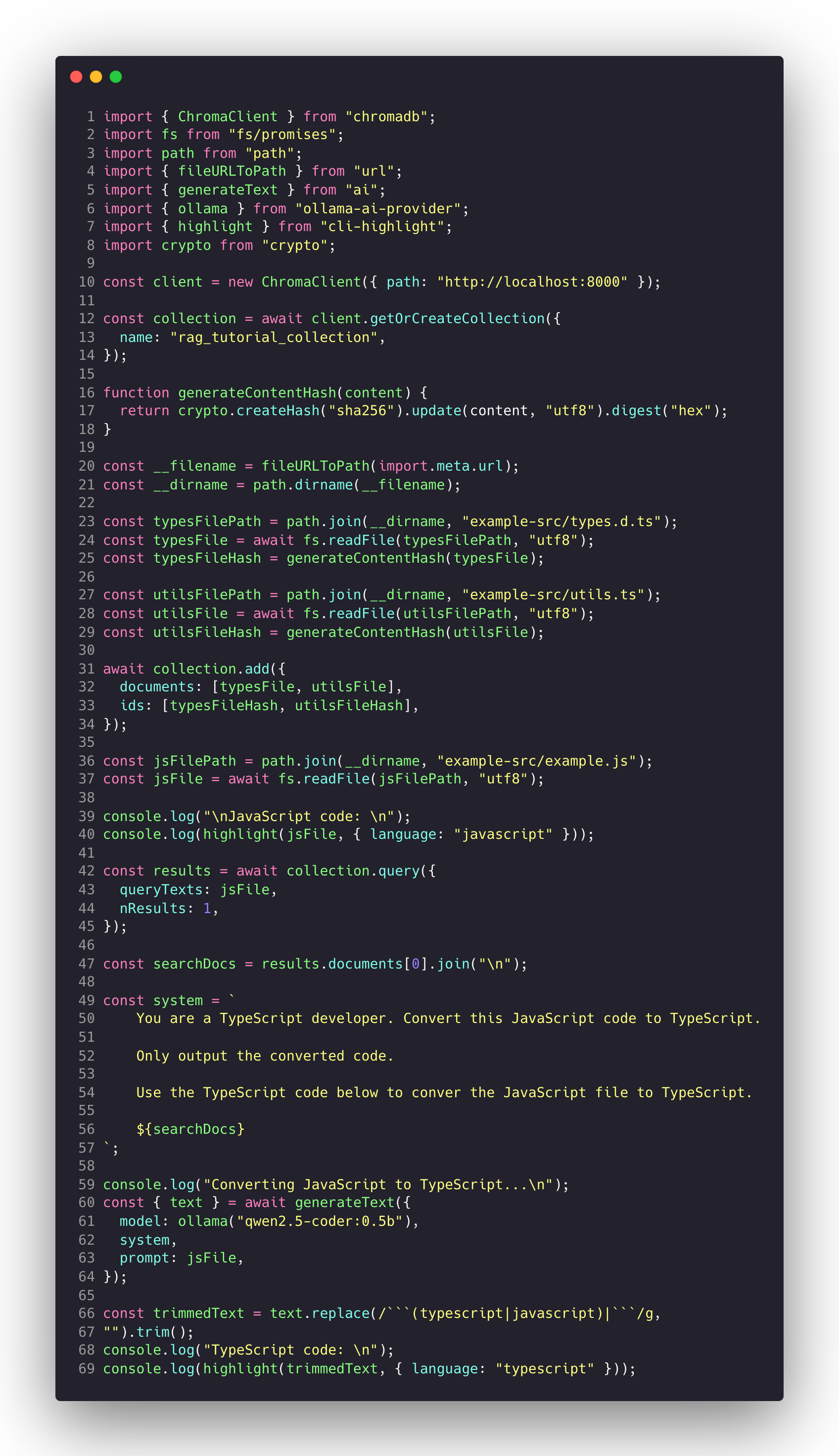
Let’s break this down. At the top we import all the deps we installed. Then we setup our Chroma client to talk to our running instance of Chroma. Then we call the client.getOrCreateCollection function to setup our collection. Then we have a function for generating a hash which is used for Chroma. Next we import our types file and our utils file. These are both pieces of example code that we are going to feed into Chroma to store for retrieval later. Once those files are read in, we then add them to our collection in Chroma. In this example we pass in documents and their associated ids respectively. The ids are generated by using the file content hashing function we created. This effectively concludes the first step of using Chroma as a DB for our files.
But what’s actually happening? Under the hood Chroma is creating embeddings of our files and storing those embeddings for us to use later. What are embeddings? Embeddings are numerical representations of data (like text, images, or code) in a multi-dimensional vector space, designed to capture their meaning, relationships, or context for computational tasks. Got it? Good.
Next we move onto querying our Chroma collection. This query is actually going to be the JS file we want to convert to TS. Why? Because we want to know is there any type information that exists based on the JS code we provide that could be helpful in generating the type information for the conversion to TypeScript. We take the information we get back from the query and join those documents together as one string. This string is then sent to the system prompt of the LLM. Then finally we instruct the LLM to convert the file to JavaScript and use the JS file as the prompt since that’s what we want to convert.
Putting it all together
Only thing left to do is run the script in your project.
pnpm tsx main.tsThis should output some freshly converted JavaScript code to TypeScript using the type information that we passed to the model.
Summary
So let’s recap. We setup Chroma and Ollama and built a simple RAG LLM system to help us convert a JavaScript codebase to TypeScript. Is this a new idea? No. Folks have built CLI tools that do this. My only issue with them all is that they require you having a subscription to OpenAI in order to do the conversion. In my opinion this is a nonstarter. Why? Privacy and data concerns.
That said, we now have a way of doing this type of conversion from JavaScript to TypeScript without using OpenAI at all thanks to Ollama and Chroma. I think utilizing open source LLMs and other technologies like Chroma is the future we should all be striving for in AI.
Let’s connect!
Thanks so much for reading! If you liked this tutorial then please let me know down below. I’m also looking to collaborate more with others on Substack writing about AI. So if that’s you then please reach out to me!