



Dead Simple Local RAG with Ollama
The simplest local LLM RAG tutorial you will find, I promise.

What is RAG?
RAG stands for Retrieval Augmented Generation. Retrieval is the process of searching for relevant documents or information from another system based on that query. Augment is the next part that takes that relevant search data and putting it into the context window of the LLM. Finally the LLM will then generate are response based on your original query using the additional information it now has within its context window.
Before we go any further it’s important to note that there is no mention of Vector DBs here at all. I feel like when I come across other RAG tutorials you always see Vector DBs as a pivotal part of this AI framework but the don’t have to be. Like all things there are tradeoffs. I’ll discuss in more detail later. Let’s get to the tutorial.
RAG Tutorial
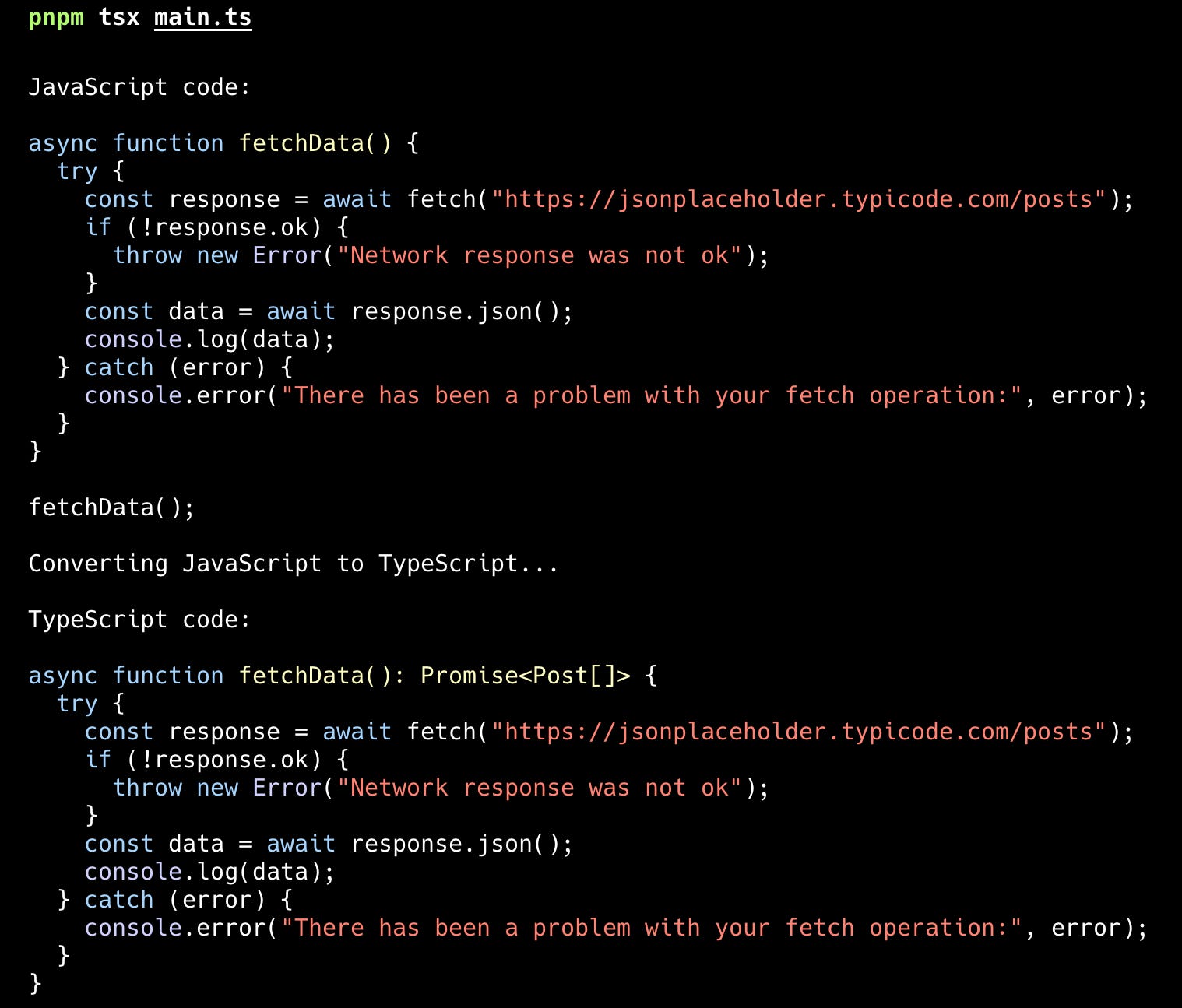
In this tutorial we are going to be leveraging a local LLM to convert a file from JavaScript to TypeScript using a simple Node.js script. It will take some example JavaScript code as input and pass that through to the local LLM for it to convert the code to TypeScript. Here is an example of what the result will look like.
This tutorial is going to use the following technologies so be sure to install these first.
Ollama - Easiest way I know of to run LLMs locally on your machine
Node.js - My JS runtime of choice
That’s it! Let’s get started.
Install Deps
There are a few dependencies we will need. In your project directory install the following.
pnpm add tsx ai ollama-ai-provider cli-highlightSince we are using TypeScript to write this we also need the Node.js types.
pnpm add -D @types/nodeExample Code
Below is the example JavaScript code we want to convert to TypeScript. This is some simple example code that it is fetching data from an endpoint containing an array of posts.

This example code will be converted to TypeScript using Ollama.
Example Type Information
Below is a file that contains some basic type information that can be used when converting the file from JavaScript to TypeScript.
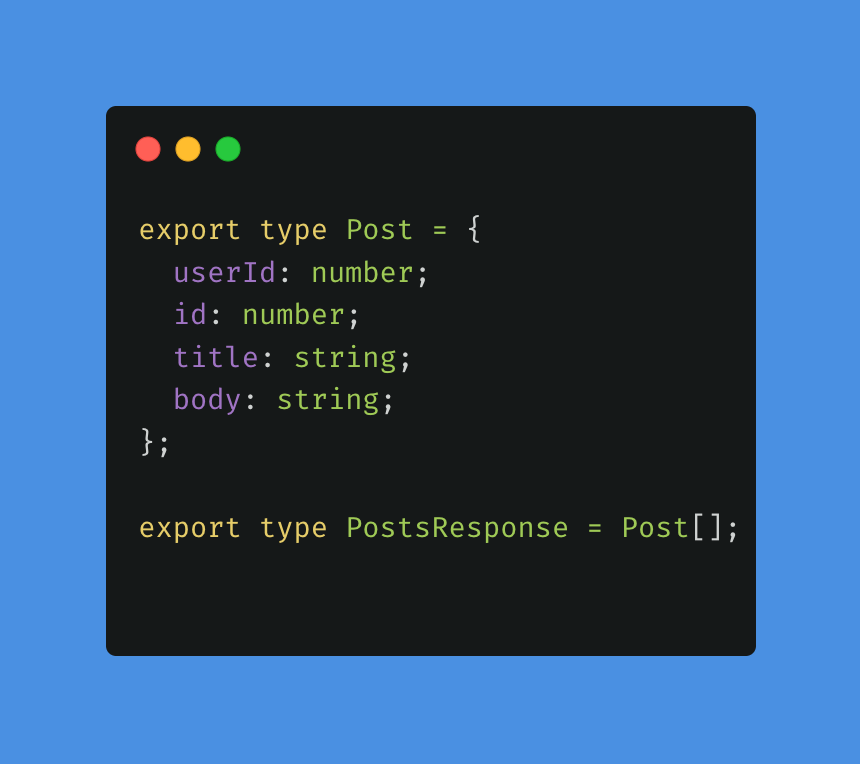
This file will be read and appended to the context window so the model can use this information during conversion.
Script for Conversion from JavaScript to TypeScript
This is the main script that is responsible for converting the JavaScript file to TypeScript using Ollama.
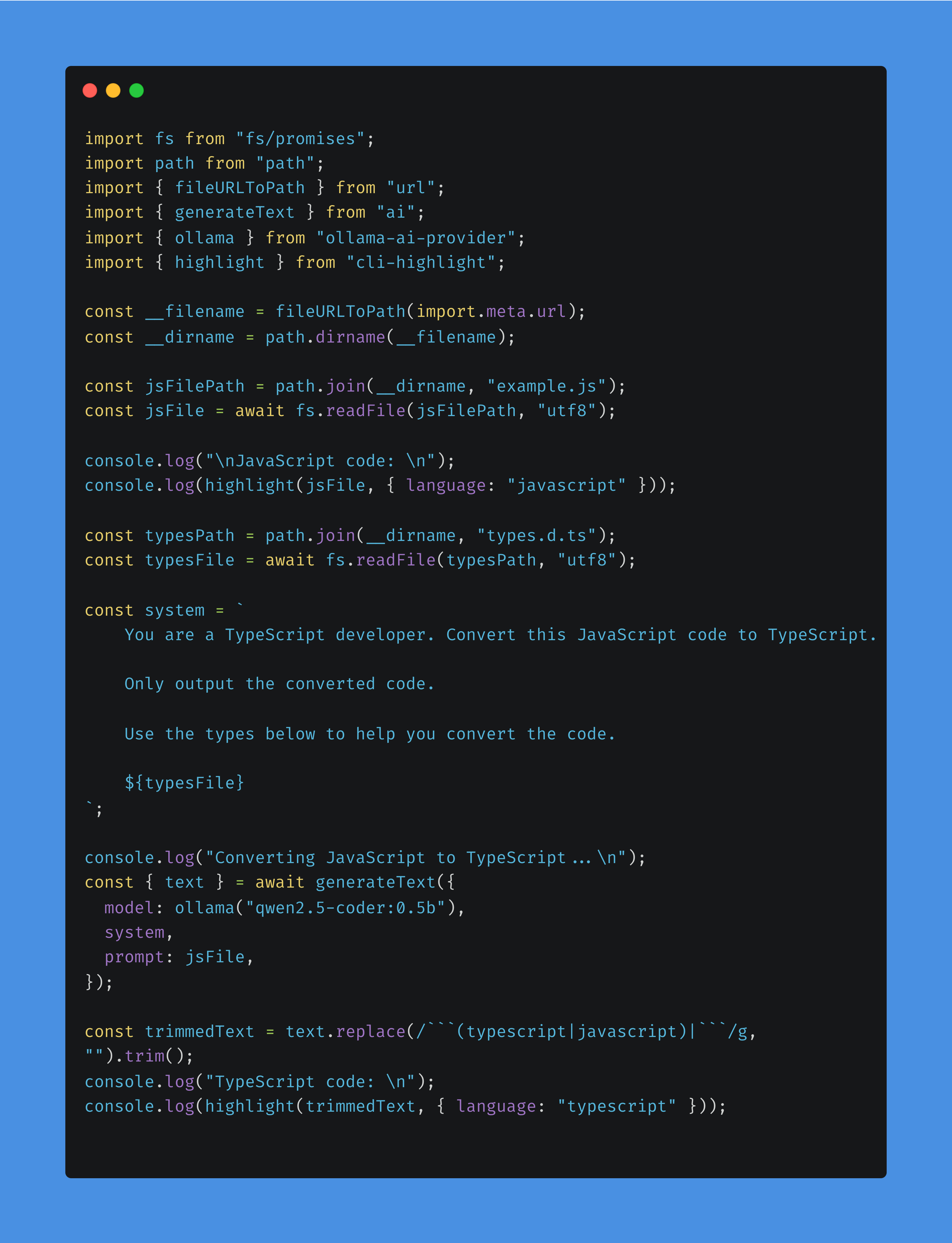
Let’s walk through this. At the top we import the deps we installed. The first thing we do is read in our example.js code that we want to convert to TS. We print it to the CLI. Then we read in our types file. This file contains some type information that the model can use when converting the file to TS. Next we have our system prompt. The system prompt informs the model how to behave when generating a response. We append the type information for the model to use here as part of its context window. We then use the generate text function to call our model using Ollama, plus our system prompt, plus the user prompt which in this case is the JS file example code. Finally, we take our text response from the model and output it to the CLI.
Ollama setup
Assuming you have Ollama installed you still have one more step to go. You need to install the model we are using in this tutorial. In this case its the qwen2.5-coder:0.5b.
ollama pull qwen2.5-coder:0.5bIt will start downloading. Once successful you can verify its there by listing your models.
ollama listPutting it all together
Only thing left to do is run the script in your project.
pnpm tsx main.tsThis should output some freshly converted JavaScript code to TypeScript using the type information that we passed to the model.
Simple RAG
To recap we built a very small but working example of what RAG can mean. At it’s core we are simply trying to provide the best information possible to the model. In our tutorial this was the process of reading in the type information and passing that to the model as part of the system prompt.
A more robust version of this involves reading in the type information and chunking it appropriately to be used in embeddings. Storing those embeddings as part of a vector DB such as ChromaDB. Searching the DB based on the file we are converting and then passing that to the model in the same way we do here. If you enjoyed this post and would like to see the more robust version of this please let me know in the comments below.
Summary
Thanks so much for reading! If you liked this tutorial then please let me know down below. I’m also looking to collaborate more with others on Substack writing about AI. So if that’s you then please reach out to me!